Download Free Version kostenlos. Erweiterte Lizenz in verschiedenen Variationen direkt bestellen
🚀 1. Einführung
MultiField OCR2DATA ermöglicht die automatische Extraktion strukturierter Daten aus PDFs und Bildern.
👉 Ziel:
Dokumente → direkt in nutzbare Daten (CSV, Excel, JSON, XML)
Dabei wird nicht nur Text erkannt, sondern gezielt strukturierte Informationen aus definierten Bereichen extrahiert und verarbeitet.
🧠 1.1 Intelligente OCR mit Selbstoptimierung (NEU)
MultiField OCR2DATA geht über klassische Texterkennung hinaus:
🔄 Automatische Mehrfacherkennung pro Feld
→ verschiedene OCR-Strategien werden kombiniert (Skalierung, Threshold, PSM)
🎯 Formatbasierte Bewertung
→ z. B. Datum, Kennzeichen oder Name werden gezielt validiert
🧪 Qualitätsbewertung mit Score & Confidence
→ beste Variante wird automatisch gewählt
👉 Ergebnis: deutlich höhere Trefferquote bei realen Dokumenten
⚡ 2. Schnellstart (5 Minuten)
- 📂 Dokumente laden
- Einzeldatei oder Verzeichnis auswählen
- Vorschau wird angezeigt
- Alternativ: 📄 Direkt scannen
- 🧩 Profil wählen oder erstellen
- Profile enthalten alle Einstellungen (Felder, Export, Quellen etc.)
- 📐 Felder definieren
- Bereiche im Dokument markieren
- Felder benennen
- 🔍 Erkennung starten
- Ergebnisse erscheinen in der Tabelle
- 📊 Exportieren
- Format wählen
- Daten exportieren
⚡ 2.1 Performance & Stabilität für große Datenmengen (NEU)
Optimiert für reale Massenszenarien:
📊 Verarbeitung von hunderten Seiten pro Lauf
⏱️ Messung von Gesamtzeit & Durchschnitt pro Datensatz
🧾 Detailliertes Logging zur Analyse und Optimierung
🧯 Absturzsichere Verarbeitung
💾 2.2 Kein Datenverlust – auch bei langen Läufen
Auch bei langen Prozessen bleibt alles erhalten:
💾 Live-Zwischenspeicherung aller Ergebnisse (CSV)
🔁 Automatische Wiederanzeige beim nächsten Start. wenn noch nicht exportiert.
📁 Logdateien für vollständige Nachvollziehbarkeit
👉 Kein Datenverlust selbst bei Abbruch oder Fehler
📂 3. Dokumente & Import
Unterstützte Formate:
- JPG / JPEG
- PNG
📁 Verarbeitung von Verzeichnissen
- ganze Ordner können verarbeitet werden
- jedes Dokument wird einzeln analysiert
📄Intelligente PDF-Verarbeitung
📑 Flexible Seitensteuerung:
- erste Seite
- bestimmte Seite
- alle Seiten automatisch
🧠 Vorab-Analyse der Dokumente
🧾 Vorschau & Steuerung pro Datei
👉 ideal für komplexe oder mehrseitige PDFs
🧩 4. Felddefinition – im Detail
Ein Feld legt fest, woher ein Wert kommt und was damit passiert.
Du kombinierst damit OCR, feste Werte und externe Datenquellen.
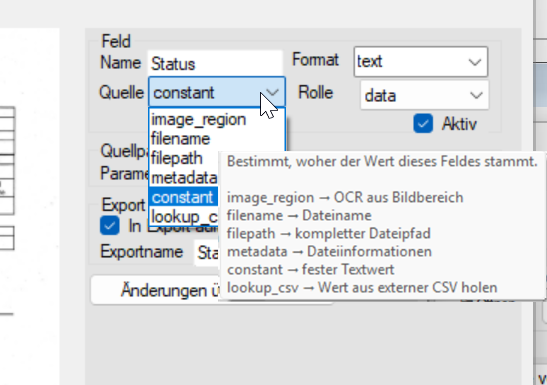
🔹 4.1 Quelle (SourceType)
Bestimmt, wo der Wert herkommt:
🖼️ image_region
Klassischer OCR-Bereich
Text wird aus einem markierten Bildausschnitt gelesen
👉 Typischer Einsatz: Rechnungen, Belege, Formulare
Beispiel:
Du markierst das Feld „Kennzeichen“ im Dokument →
OCR liest: M AB4123
📄 filename
Wert wird aus dem Dateinamen gelesen
👉 Gut für: IDs, Referenzen, Batch-Infos
Beispiel:
Datei: Rechnung_4711.pdf → Ergebnis: 4711
📁 filepath
Verwendet den kompletten Dateipfad
👉 Gut für: Struktur- oder Ablageinformationen
Beispiel:C:\Import\KundeA\Rechnung.pdf →
kann später genutzt werden, um „KundeA“ zu erkennen
🔢 constant
Fester, immer gleicher Wert
👉 Gut für: Tags, Kategorien, Importkennzeichen
Beispiel:
Wert: Import2026 → steht in jeder Zeile im Export
🧾 Metadata
Metadaten sind automatisch ermittelte Informationen zur Datei.
Diese können z. B. für Dateinamen, Exportfelder oder OCR-Zuordnungen verwendet werden.
📂 Allgemeine Dateiinformationen
👉 Beispiele: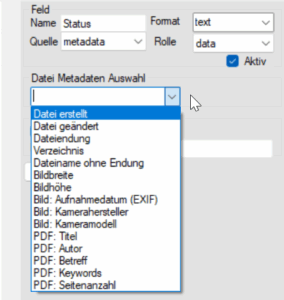
- Erstellungsdatum
- Änderungsdatum
- Dateiendung
- Verzeichnis
- Dateiname ohne Endung
Beispiel:Rechnung_2026-04-09.pdf
🖼️ Bild-Metadaten (EXIF)
👉 Verfügbar bei Bilddateien (z. B. JPG, PNG)
- Aufnahmedatum (EXIF)
- Kamerahersteller / Modell
- Bildbreite / Höhe
Beispiel:IMG_2024-08-15_Canon_EOS80D.jpg
📄 PDF-Metadaten
👉 Verfügbar bei PDF-Dateien
- Titel
- Autor
- Betreff
- Keywords
- Seitenanzahl
Beispiel:Vertrag_MaxMustermann_12Seiten.pdf
⚙️ Systemwerte (intern)
👉 Werden während der Verarbeitung erzeugt
- Zeitstempel (Verarbeitungszeit)
- Laufende Nummer
- Seitenindex (bei Mehrseiten-Dokumenten)
Beispiel:2026-04-09_10-15_Seite1
💡 Hinweis
Nicht alle Metadaten sind bei jeder Datei verfügbar:
- Bilddaten nur bei Bildern mit EXIF
- PDF-Daten nur bei PDFs mit hinterlegten Metadaten
🔗 lookup_csv (Daten verknüpfen)
Wert wird aus einer externen CSV-Datei nachgeschlagen
💡 Idee:
Daten aus Dokumenten mit externen Daten kombinieren
👉 Prinzip:
Du hast einen erkannten Wert → suchst damit etwas in einer Tabelle → bekommst einen anderen Wert zurück
🔧 Funktionsweise:
- OCR liest Schlüssel (z. B. Schlüssel, Kundennummer, Kennzeichen)
- Wert wird intern gespeichert
- Lookup greift darauf zu
- Rückgabewert wird gesetzt
Beispiel (CSV):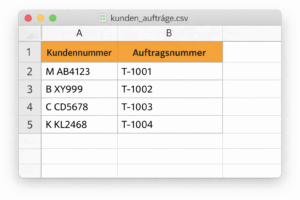
M AB4123;T-1001
B XY999;T-1002
Ablauf:
OCR liest: M AB4123 →
Suche in CSV →
Ergebnis: T-1001
👉 Typischer Einsatz:
- Kundennummer→ z.B. Auftragsnummer, Ticketnummer
- Artikelnummer → Artikelname
- Kundencode → Kundenname
🔎 Erweiterte Lookup-Logik (NEU)
🔗 Unterstützung von mehreren CSV-Dateien
✨ Wildcards möglich:
datenbank*.csv→ mehrere Dateien werden automatisch kombiniert
🧠 Integriertes Caching für maximale Geschwindigkeit
👉 ideal für große Datenbestände und komplexe Zuordnungen
🔹 4.2 Rolle (FieldRole)
Bestimmt, wie das Feld verwendet wird:
data
Feld wird exportiert
👉 Standardfall
Alles, was in deiner Ergebnisliste oder CSV landen soll
helper
Feld wird nicht exportiert, dient nur intern
👉 Sehr wichtig für Logik / Zwischenschritte
Beispiel:
- OCR liest Schlüssel, Kundennummer, Kennzeichen, usw. →
M AB4123(helper) - lookup_csv nutzt dieses Feld → liefert z.B: Auftragsnummer oder Ticketnummer, usw.
- Nur die aus der zusätzlichen CSV Datei ermittelte Auftragsnummer wird exportiert
action_only (optional / zukünftig)
Feld wird für Aktionen oder Automationen verwendet
👉 aktuell vorbereitet für spätere Erweiterungen
(z. B. Trigger, Workflows, Weiterverarbeitung)
💡 Typischer Workflow (vereinfacht)
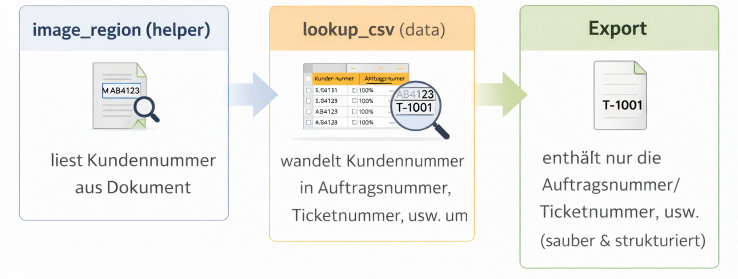
- image_region (helper)
→ liest Kundennummer aus Dokument - lookup_csv (data)
→ wandelt Kundennummer in Auftragsnummer, Ticketnummer, usw. um - Export
→ enthält nur die Auftragsnummer/Ticketnummer, usw. (sauber & strukturiert)
🔹 4.3 Export
- „In Export aufnehmen“ aktivieren
- Spaltenname definieren
👉 Reihenfolge wichtig:
- entspricht der Reihenfolge in der Feldliste
- kann über Hoch/Runter geändert werden
🔍 5. OCR-Bereiche richtig definieren
✔ möglichst kleiner, präziser Bereich
✔ nur relevanten Text erfassen
✔ keine großen Ränder
👉 verbessert Genauigkeit und Performance
📍 6. Referenzanker (Positionskorrektur)
Problem:
Scans sind oft leicht verschoben
Lösung:
👉 Referenzfeld definieren
🔧 Funktionsweise:
- ein fester Bereich wird gesucht (z. B. Überschrift)
- daraus wird ein Offset berechnet
- alle anderen Felder werden angepasst
⚠️ Best Practices:
✔ festen Text wählen (nicht variabel!)
✔ möglichst kleiner Bereich
✔ hoher Kontrast
🚨 Performance-Hinweis:
- je größer der Referenzbereich → desto langsamer
- kleine, präzise Referenz = deutlich schneller
💡 Hinweis:
- Referenzfeld wird nicht exportiert
- dient nur zur Ausrichtung
👉 Ergebnis:
✔ stabile Erkennung auch bei verschobenen Scans
✔ deutlich weniger Fehlzuordnungen
🧪 7. Formate & Datenaufbereitung
Formate sorgen dafür, dass Daten direkt nutzbar sind.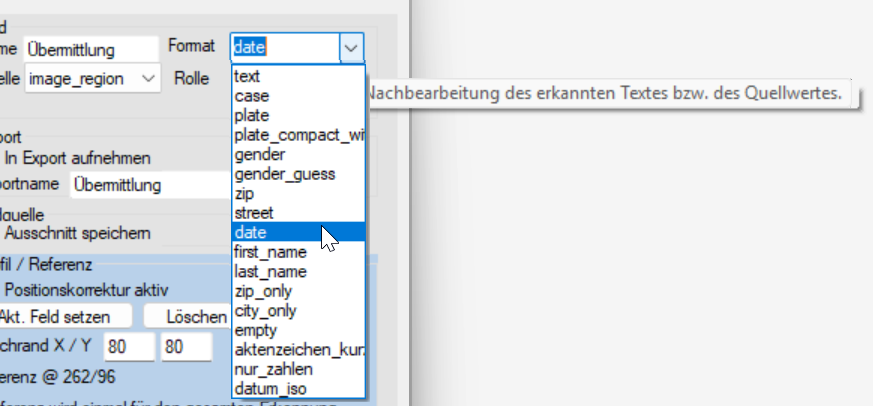
Beispiele:
Kennzeichen
- entfernt Leerzeichen / normalisiert
Datum
- wandelt in gewünschtes Format
Name
- trennt Vor- und Nachname
Anrede (Gender)
- basiert auf Vornamenliste
- interne CSV wird genutzt
👉 Ergebnis:
- Herr / Frau automatisch bestimmbar
🔹 7.1 Vornamenliste für automatische Anrede Bestimmung aus Vorname
Wird die Anrede wird als Datenexport benötigt, jedoch im Dokument ist lediglich der Vorname enthalten?
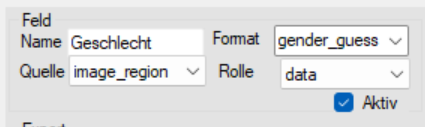
Lösung: als Format „gender_guess“ auswählen.
Zuvor in den Programm Einstellungen sicherstellen, dass eine Liste, mit Vornamen und dem zugehörigen Geschlecht als Referenz/Nachschlagewerk eingestellt ist.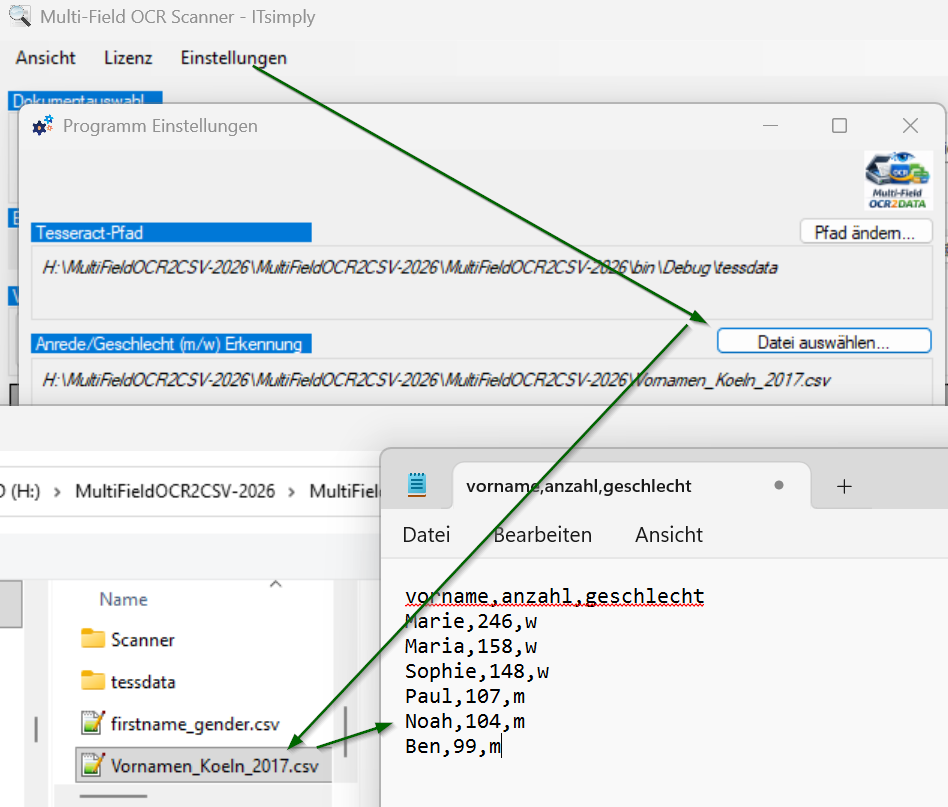
💡 Erweiterbar:
- eigene Formate möglich
🖼️ 8. Vorschau & Kontrolle
Nach der Erkennung:
- Daten werden in Tabelle angezeigt
- Bildausschnitte sichtbar
- Ergebnisse überprüfbar
✏️ Manuelle Korrektur:
👉 Werte können direkt angepasst werden
vor dem Export
📊 9. Export
Formate:
- CSV
- Excel
- JSON
- XML
- HTML
Funktionen:
- Reihenfolge steuerbar
- Felder auswählbar
- Trennzeichen definierbar
💡 Spezialfall:
Feld existiert nicht im Dokument?
👉 Lösung:
- helper + lookup_csv verwenden
🧾 Flexible Dokumentausgabe mit HTML-Vorlagen
Mit dem neuen HTML-Export bietet MultiField OCR2DATA eine besonders flexible Möglichkeit, erkannte Daten neben den tabellarischen Exportmöglichkeiten per CSV, Excel oder XML nun auch zusätzlich die Möglichkeit, die erkannten Datenfelder direkt in individuell gestaltete Dokumente umzuwandeln.
🧩 Individuelle Vorlagen statt starrer Exporte
Anstatt nur strukturierte Daten (CSV, Excel, JSON) zu exportieren, können jetzt:
- 📄 eigene HTML-Vorlagen definiert werden
- 🎨 Layout und Darstellung frei gestaltet werden
- 🔄 erkannte Felder werden automatisch eingesetzt
👉 Ideal für:
- Anschreiben
- Berichte
- Dokumentationen
- oder weiterverarbeitbare Druckvorlagen
📁 Automatische Dokumenterstellung
Für jeden Datensatz wird automatisch eine eigene Datei erzeugt:
- 🧾 Ein Dokument pro Scan / Datensatz
- 🏷️ frei definierbarer Dateiname (z. B.
Dokument_{{Index}}_{{Datei}}.html) - 📂 Ausgabe in beliebigen Zielordner
⚙️ Benutzerfreundlicher Template-Editor
Die HTML-Vorlagen lassen sich direkt im Programm bearbeiten:
- ✏️ integrierter Editor für schnelle Anpassungen
- 📋 Übersicht aller verfügbaren Platzhalter
- 💾 Vorlagen zentral speicherbar und wiederverwendbar
👉 Auch ohne tiefere HTML-Kenntnisse lassen sich einfache Layouts schnell erstellen.
🧠 Intelligente Datenaufbereitung
In Kombination mit den bestehenden Funktionen profitieren HTML-Exporte zusätzlich von:
- 🧠 intelligenter OCR-Nachbearbeitung
- 🎯 formatbasierter Erkennung (z. B. Datum, Kennzeichen, Namen)
- 👤 automatischer Anrede-Ermittlung (z. B. über Vornamen-Genderliste)
👉 Ergebnis: direkt verwendbare, strukturierte Dokumente statt Rohdaten
🚀 Praxisvorteil
Der HTML-Export schließt die Lücke zwischen Datenerfassung und Dokumentenerstellung:
Scan → OCR → strukturierte Daten → fertiges Dokument🧰 9. ENTWICKLER / FLEXIBILITÄT
🧰 Entwicklerfreundlich & flexibel
🧩 Modulare Felddefinitionen
🧠 Helper-Felder für komplexe Datenlogik
🔁 Erweiterbar ohne externe KI
👉 ideal für individuelle Workflows und Spezialfälle
⚡ 10. Profile
Profile speichern:
- Felddefinitionen
- Exporteinstellungen
- Pfade
- Formate
👉 mehrere Anwendungsfälle parallel möglich
🔄 11. Typischer Workflow
- Beispiel-Dokument laden bzw. direkt scannen
- Felder definieren
- Referenz setzen (optional)
- Formate anwenden
- Lookup konfigurieren
- testen
- Profil speichern
- Batch starten
❗ 12. Häufige Probleme
Feld leer
→ OCR-Bereich prüfen
Lookup funktioniert nicht
→ Schreibweise prüfen
→ Format anwenden
falsche Werte
→ Bereich zu groß
→ Format fehlt
📄 13. Direkt scannen (integrierte Funktion)
Neben dem Import von Dateien können Dokumente auch direkt eingescannt werden.
👉 Funktion: „📄 Direkt Scannen…“
🔧 Funktionsweise
- Scanner wird direkt aus der Anwendung heraus angesprochen
- gescannte Seiten werden automatisch in die Verarbeitung übernommen
- Vorschau und OCR stehen sofort zur Verfügung
💡 Einsatzmöglichkeiten
✔ Einzelne Dokumente schnell erfassen
✔ Papierdokumente ohne Zwischenschritte digitalisieren
✔ direkt in bestehende Profile einlesen
⚠️ Hinweise
- bei mehreren Seiten empfiehlt sich:
- entweder Einzel-Scan pro Dokument
- oder Nutzung eines Einzugsscanners
👉 optimal: ein Dokument = eine Seite
💡 Tipp
Die Scanner-Funktion eignet sich ideal für:
👉 spontane Erfassung einzelner Dokumente
👉 kleinere Arbeitsmengen ohne vorherige Dateiablage
Für große Mengen empfiehlt sich weiterhin der Import aus einem Verzeichnis.
🔮 14. Ausblick
Geplante Erweiterungen:
- erweiterte Aktionen (z. B. API-Aufrufe)
📥 Fazit
MultiField OCR2DATA ist mehr als ein OCR-Tool:
👉 es ist ein flexibles System zur Datenautomatisierung
Mit:
- Feldlogik
- Referenzanker
- CSV-Verknüpfung
- Formatregeln
lassen sich selbst komplexe Dokument Prozesse automatisieren.
💡 Tipp:
Ein gut eingerichtetes Profil spart dauerhaft Zeit – oft schon nach wenigen Dokumenten.
🧪 Praxiserprobt
Das System wurde bereits mit großen Datenmengen getestet:
✔ hunderte Seiten pro Lauf
✔ stabile Verarbeitung über längere Zeiträume
✔ nachvollziehbare Ergebnisse durch Logging

Von Dokument zu Daten in Sekunden: OCR mit strukturierter Felderkennung und Export in Excel, CSV & mehr.
👉 Zur Produktseite