
Einleitung
Ein ZFS-Pool in TrueNAS zeigt plötzlich den Status DEGRADED.
Im Internet liest man häufig sofort:
„Platte tauschen. Keine Experimente.“
Das ist die sicherste Lösung – aber nicht immer die einzig sinnvolle.
Gerade bei einmaligen I/O-Fehlern, Stromausfällen oder Kabelproblemen kann ein vorschneller Austausch unnötig sein.
In diesem Artikel zeige ich, wie man einen degradierten Pool sachlich bewertet – und wann ein Austausch wirklich notwendig ist.
Was bedeutet „DEGRADED“ überhaupt?
Ein Pool ist DEGRADED, wenn mindestens ein Gerät (VDEV) nicht mehr voll funktionsfähig ist, aber noch genügend Redundanz vorhanden ist.
Beispiel bei einem Mirror:
mirror-0disk1 ONLINEdisk2 FAULTED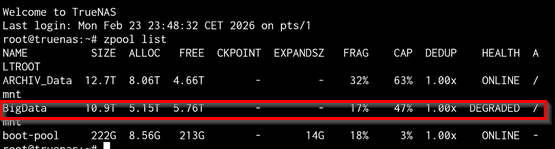
Das bedeutet:
-
Die Daten sind noch vollständig vorhanden.
-
Der Pool funktioniert weiter.
-
Aber es gibt keine Redundanz mehr.
-
Ein weiterer Ausfall würde zu Datenverlust führen.
Wichtig:
DEGRADED heißt nicht automatisch Datenverlust.
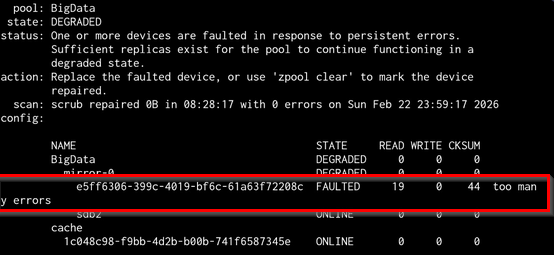
Warum faulted ZFS eine Platte?
ZFS ist extrem defensiv. Schon relativ wenige Fehler können dazu führen, dass eine Platte als FAULTED markiert wird.
Typische Ursachen:
-
SATA-Kabel locker oder defekt
-
Controller-Timeout
-
Stromausfall oder Spannungsschwankung
-
Backplane-Kontaktproblem
-
kurzfristiger I/O-Hänger
Im Status sieht man dann z. B.:
READ: 19CKSUM: 44too many errorsDas bedeutet:
-
ZFS hat fehlerhafte oder inkonsistente Blöcke gesehen
-
Die Redundanz konnte die Daten rekonstruieren
-
Zur Sicherheit wurde das Gerät deaktiviert
Das heißt aber noch nicht zwingend: „Mechanischer Defekt“.
SMART sagt „OK“ – und trotzdem Fehler?
Das ist ein häufiger Irrtum.
SMART prüft:
-
Reallocated Sectors
-
Pending Sectors
-
Oberflächentest (bei Long-Test)
-
interne Elektronik
SMART erkennt jedoch keine:
-
einmaligen Controller-Timeouts
-
Kabelprobleme
-
Stromprobleme
-
Bus-Reset-Fehler
Deshalb kann ein SMART-Test fehlerfrei sein, während ZFS I/O-Fehler gesehen hat.
Schritte zum wieder Online setzen des Mirror
Angenommen, der Name des Pool lautet „BigData“, kann nach vorherigen Festplattentest und Abwägung, ob ein erneutes Verbinden der abgewählten Festplatte sinnvoll ist, folgende Schritte ausgeführt werden:
zpool clear "BigData"
zpool status "BigData"
Wann ist zpool clear sinnvoll?
Ein zpool clear setzt den Fehlerstatus zurück und erlaubt ZFS, das Gerät erneut einzubinden.
Sinnvoll ist das vor allem wenn:
-
Ein Mirror oder RAIDZ vorhanden ist
-
SMART keine kritischen Werte zeigt
-
Fehler einmalig waren
-
Ein Stromausfall vorausging
-
Nach einem Hardware-Umbau Fehler auftraten
-
Ein Scrub keine Datenfehler meldet
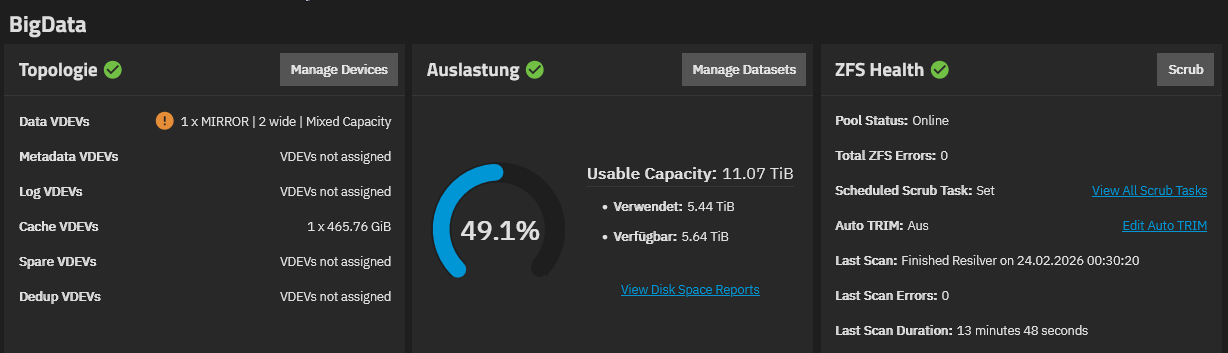
Nach dem Clear startet in der Regel automatisch ein Resilver, also eine vollständige Neusynchronisation.
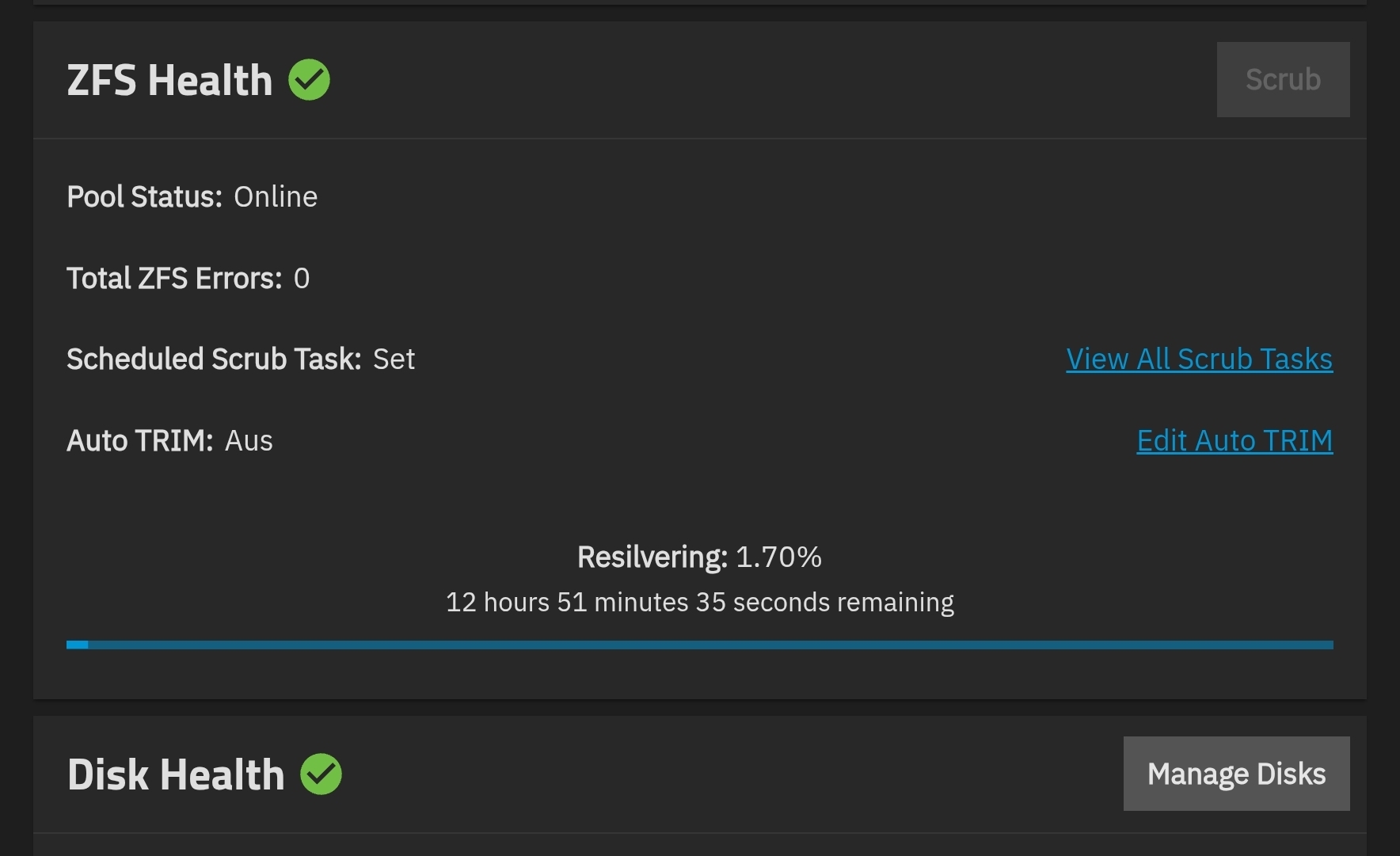
Wenn dieser sauber durchläuft, war die Platte möglicherweise nicht defekt.
Wann sollte man sofort tauschen?
Hier gibt es keine Diskussion – die Platte muss ersetzt werden, wenn:
-
Reallocated Sectors steigen
-
Pending Sectors vorhanden sind
-
Fehler sofort wieder auftreten
-
Die Platte mehrfach FAULTED wird
-
SMART „Pre-Fail“ meldet
-
Geräusche oder Aussetzer auftreten
ZFS ist nicht grundlos streng. Wenn sich Fehler wiederholen, ist das kein Zufall.
Praxisempfehlung
Vorgehen bei DEGRADED:
-
zpool statusprüfen -
SMART-Werte prüfen
-
Scrub durchführen
-
Falls plausibel →
zpool clear -
Resilver vollständig abwarten
-
Danach Long SMART Test
Erst wenn danach erneut Fehler auftreten → tauschen.
Das ist technisch sauber und vermeidet unnötige Hardwarekosten.
Fazit
Nicht jeder „DEGRADED“-Status bedeutet sofort einen Plattendefekt.
ZFS reagiert bewusst aggressiv, um Daten zu schützen.
Mit einer strukturierten Analyse lässt sich oft klären, ob ein Austausch zwingend notwendig ist – oder ob es sich um einen einmaligen I/O-Vorfall handelt.